Indexing Pages that Aren’t Yours!
Table of contents
- Indexing Pages that Aren’t Yours!
Ever had a need to index pages that are not yours? Here’s a legal hack on how to do it! In this blog post, we take a deep dive into the intricacies of getting third-party web pages indexed by Google, which can be quite a challenge if it’s not your own site. This guide is particularly valuable for SEO enthusiasts, website owners, and digital marketers who aim to maximise their online presence.
This article explores steps to have Google index pages that do not belong to you. For pages that actually belong to you, the approch is much simpler and will be covered in a separate article!
The Importance of Indexing Pages
Before we delve into the “how,” let’s start with the “why.” When a page is not indexed by Google, it essentially doesn’t exist in the eyes of search engines. This can have several ramifications:
- Backlink and Citation Recognition: If your website is listed in a directory but the page isn’t indexed, Google doesn’t acknowledge the backlink and citations.
- SEO Impact: Unindexed pages can affect your Local SEO efforts and overall site authority.
Directory Pages Containing Pet Coach Listings
We have our website listed in a couple of directories for Local SEO purposes. You can check it out for yourselves in the links below!
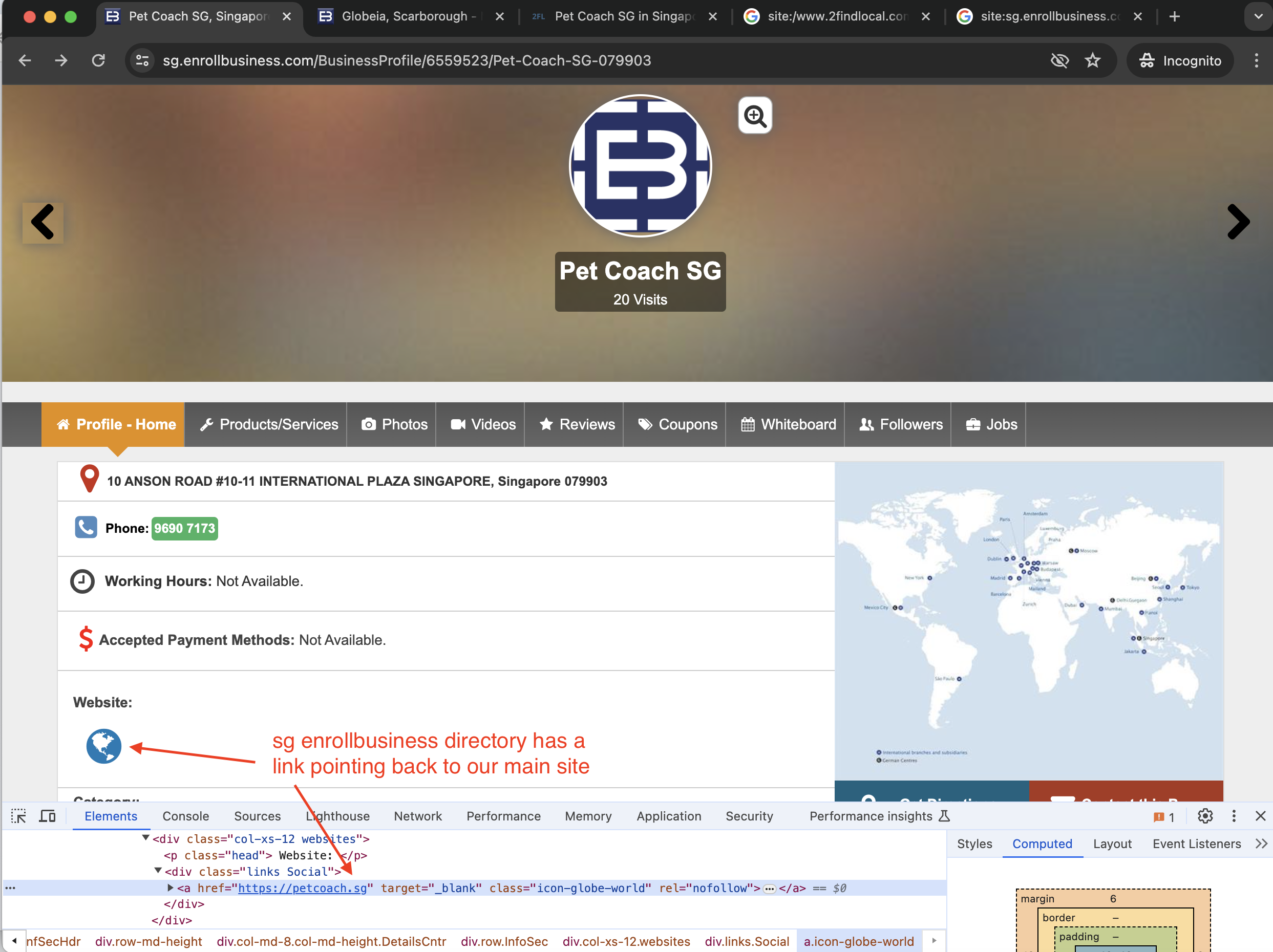
As the directory listings contains links to our site, we can expect Google Search Console to recognize backlinks that originates from the directory to our site.
But as we can see in the subsequent sections, these are missing ><.
Missing Backlinks
Upong checking Google Search Console, we noticed that the backlinks from the directories are actually not registered by Google! Why!?
Here’s a screenshot from our Google Search Console showing the absence of these backlinks:
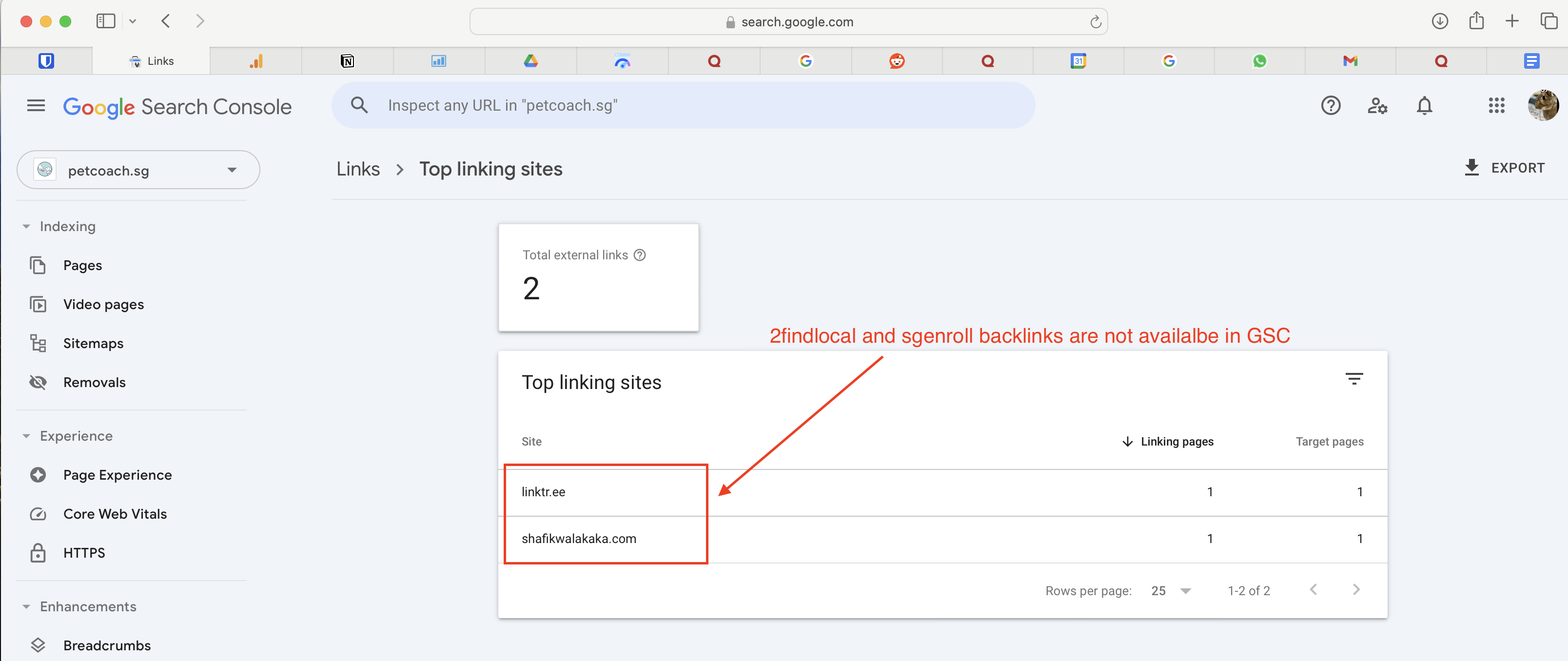
We can see that there are no backlinks recognized by Google Search Console (GSC), from either 2findlocal or sgenroll.
Now, we need to dig deeper to understand why these links are not registered by GSC.
Google can only register Backlinks on Indexed Pages
Upon further investigation, we realized that Google can only register backlinks on indexed pages. This makes absolute sense, because Google needs to crawl the page, before it can identify a backlink to our site exists. Since the page is not indexed/crawled, how can Google identify that a backlink exist!
See this discussion in Quora for details: 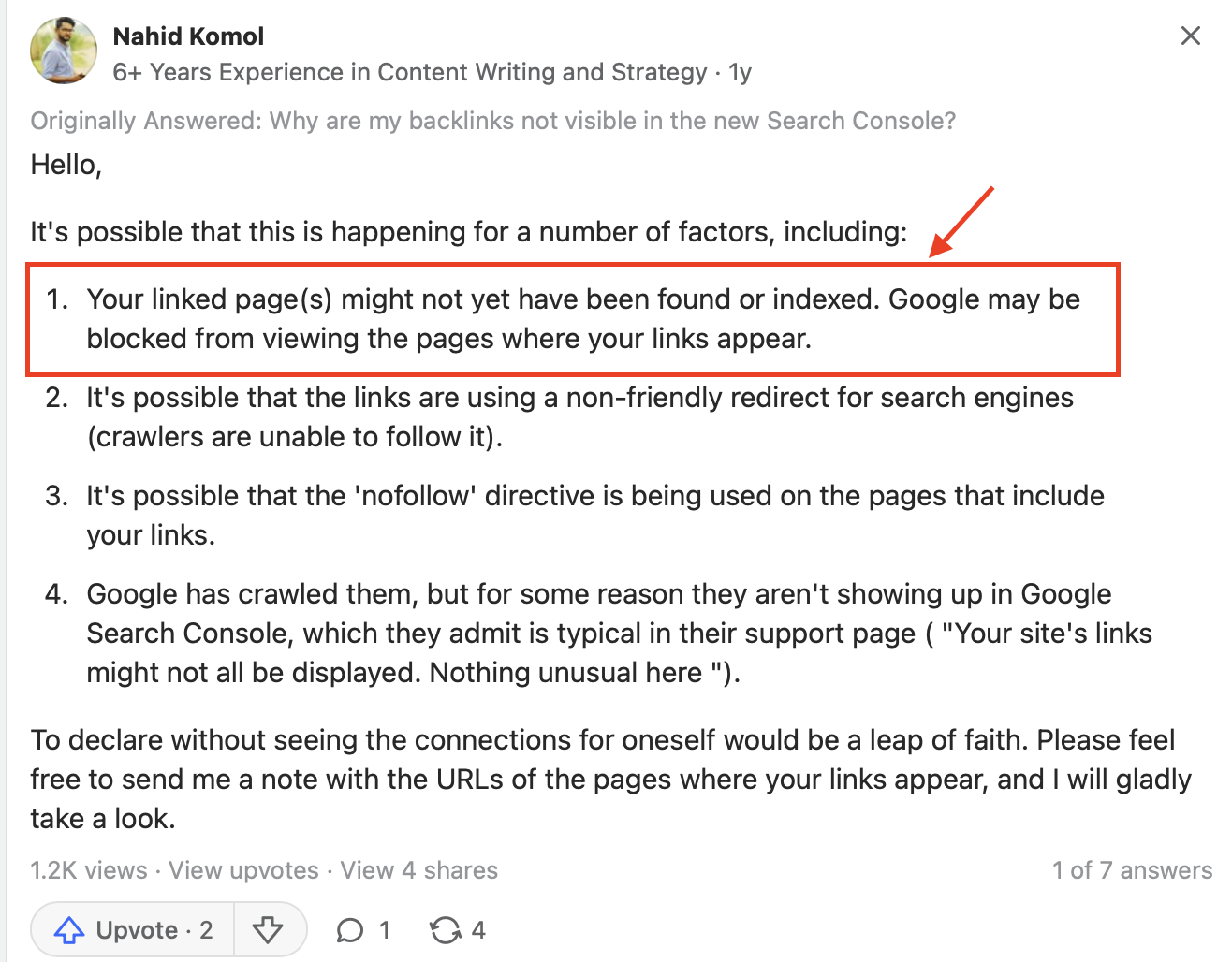
So our next step, is to verify whether the directory pages are indeed indexed or not!
Verify whether directory pages are indexed
How to check if pages are indexed
In google search console, we can easily check for whether a page is indexed by searching for site:<full website url>. Try it yourself!
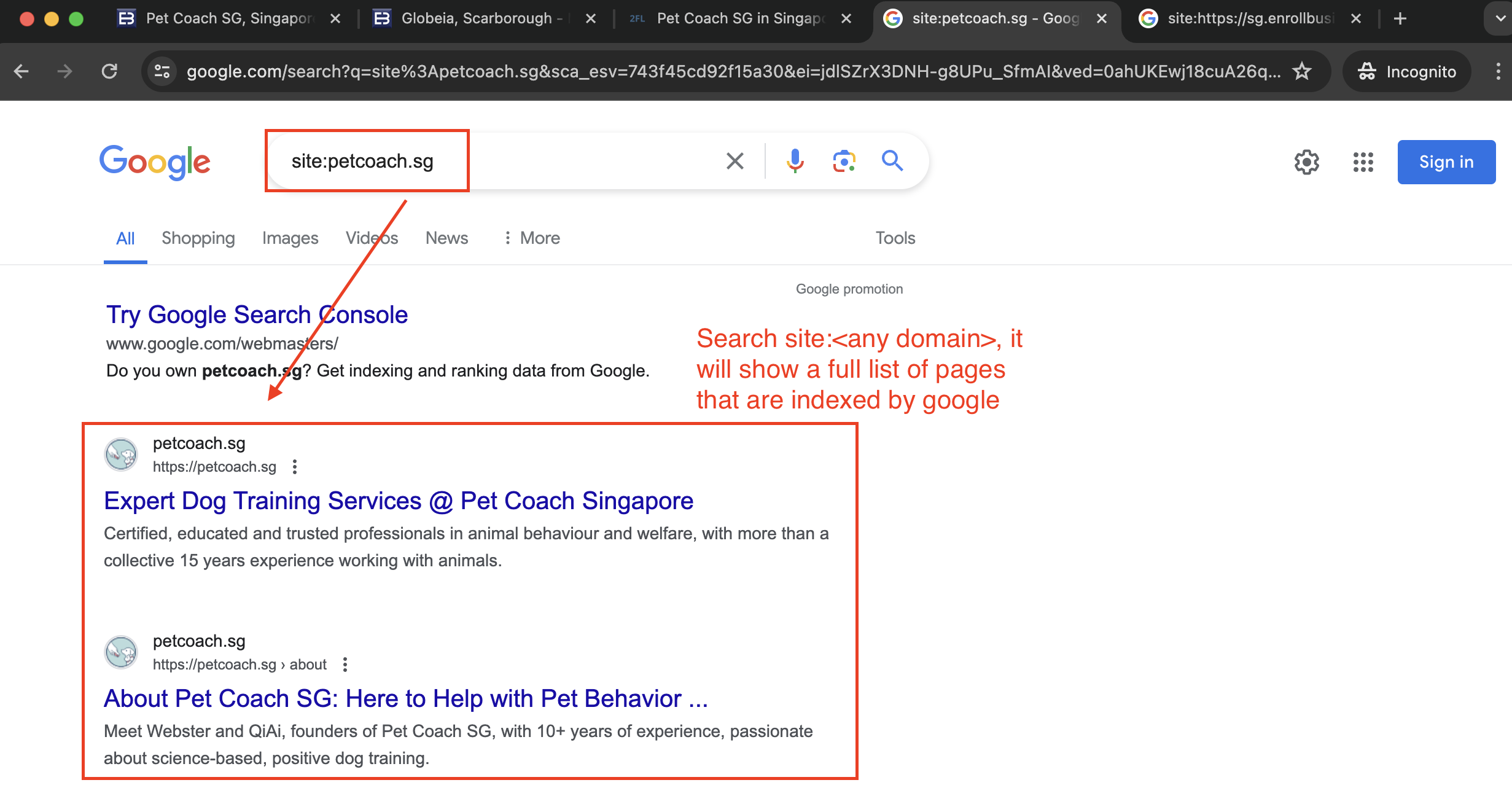
For us, we are interested in the following links:
https://sg.enrollbusiness.com/BusinessProfile/6559523/Pet-Coach-SG-079903https://www.2findlocal.com/b/15096552/pet-coach-sg-singapore
So, we’ll run the google site search against these URLs and see if the pages are indexed.
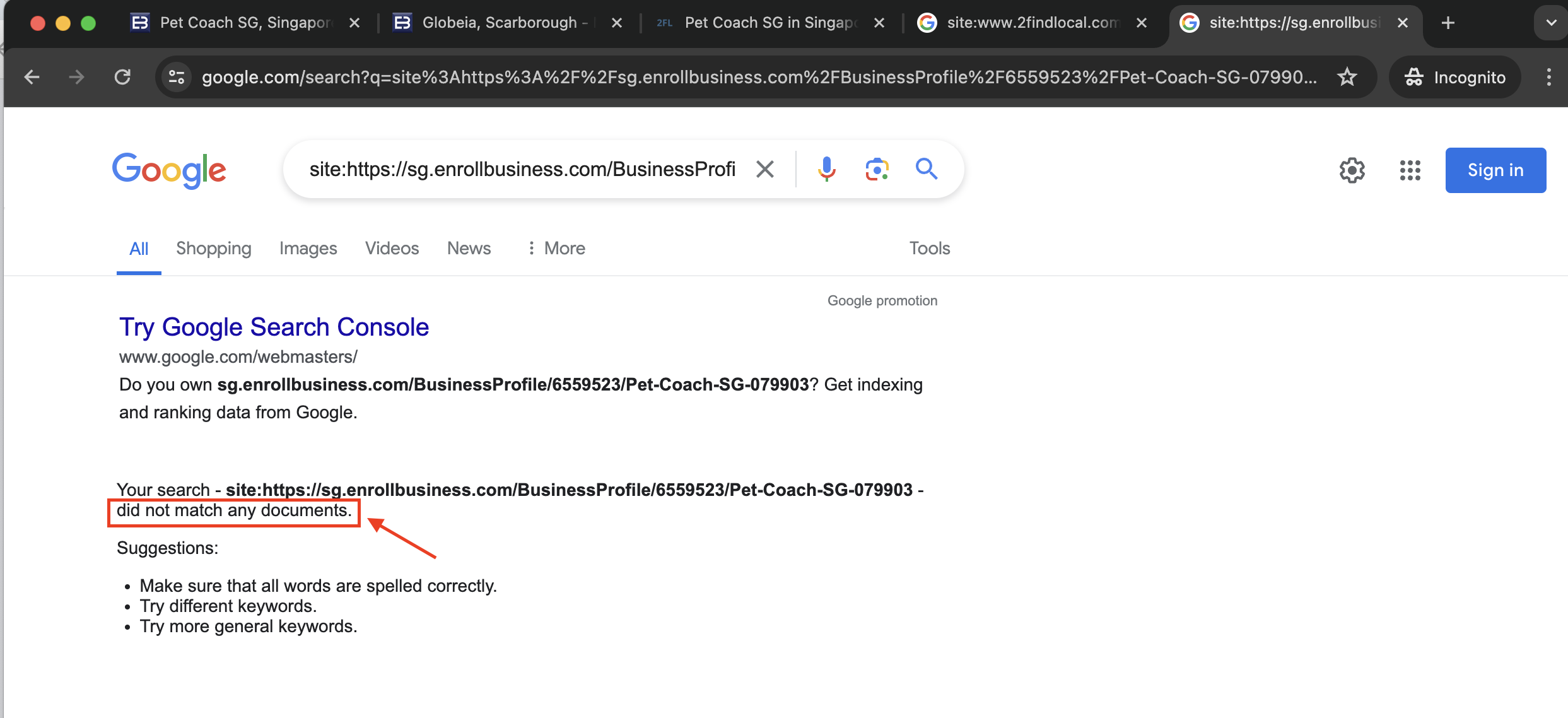
Results for indexing status - sg.enrollbusiness.com
We noticed that the sgenroll directory listing was not indexed. See the steps performed below for reference:
- Access google search and search for
site: sg.enrollbusiness.com/BusinessProfile/6559523/Pet-Coach-SG-079903. - You will see that there are not results found.
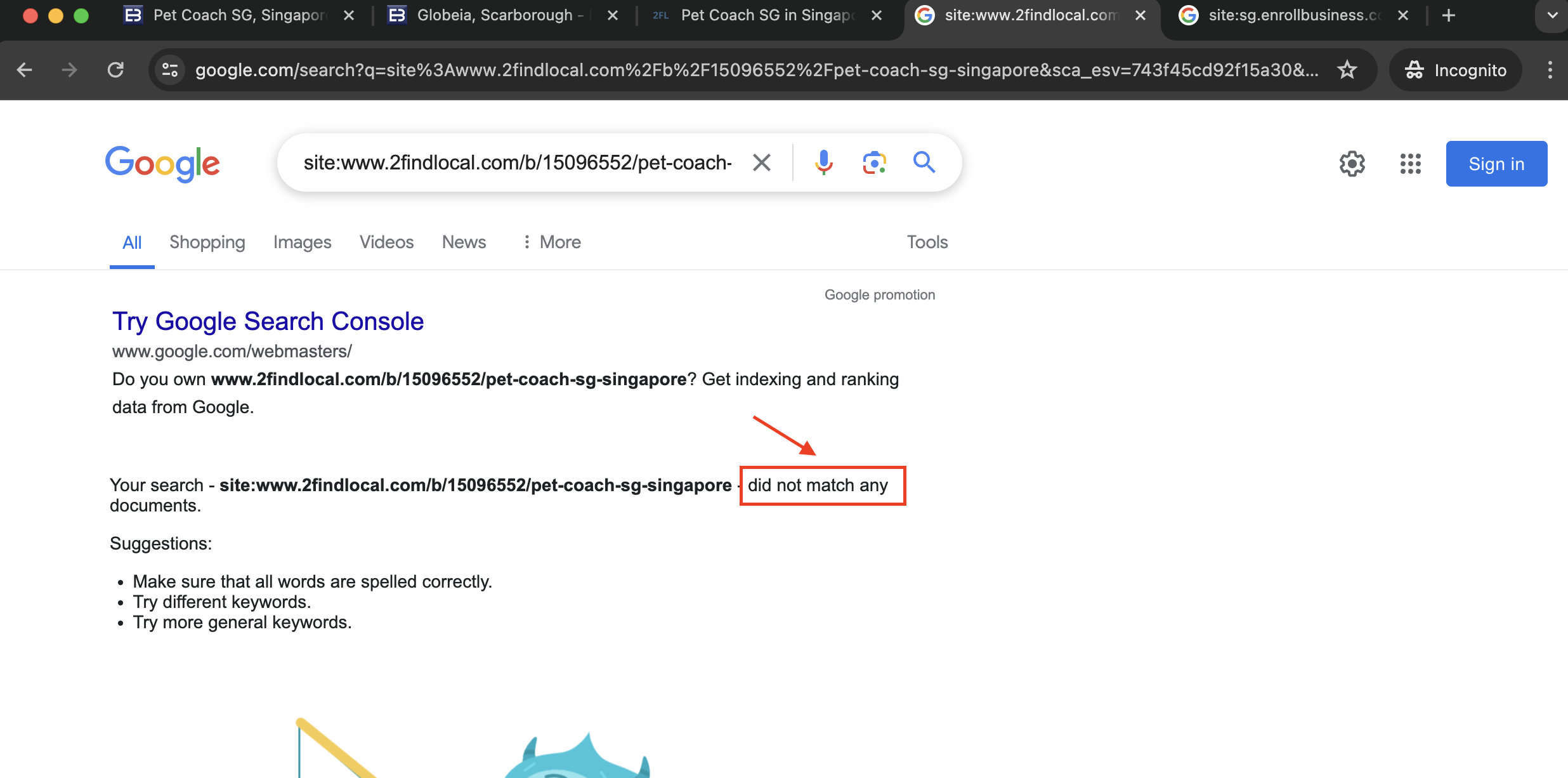
Results for indexing status - 2findlocal.com
We also realized that the 2findlocal directory listing is also not indexed ><! Same steps were done to complete the check:
- Access google search and search for
site: www.2findlocal.com/b/15096552/pet-coach-sg-singapore. - You will see that there are not results found.
The Hypothesis
Now, our hypothesis stands as follows:
- Google must crawl pages that contains backlinks before it can recognize a backlink
- Google has not indexed the directory listing page (containing our listing). This could be for various reasons (e.g., no inbound link etc.)
- Based on the above two, it is expected that the backlink does not show up in our GSC
To further confirm this hypothesis, we must try to get the directory listing page indexed. Once the directory listing page is indexed, we should check our GSC for our backlink profile:
- If our backlink profile contais the directory listing after the directory is indexed, our hypothesis is accurate
- Else, we are back to square one (pray to god this is not the case, for our sanity ><>)
The Plan to Experiment and Index a 3rd Party Page
All that chat above leads us to our next step, how to index a 3rd party page. And the plan is as follows:
Step 1: Check if the directory page can be Indexed
The site owner could have provided settings in robots.txt or robots meta tags that will prevent Google from ever indexing the page. We need to check if this is the case.
The check was done in the following steps:
- Check the
robots.txtfile to ensure it’s not blocking Google bots.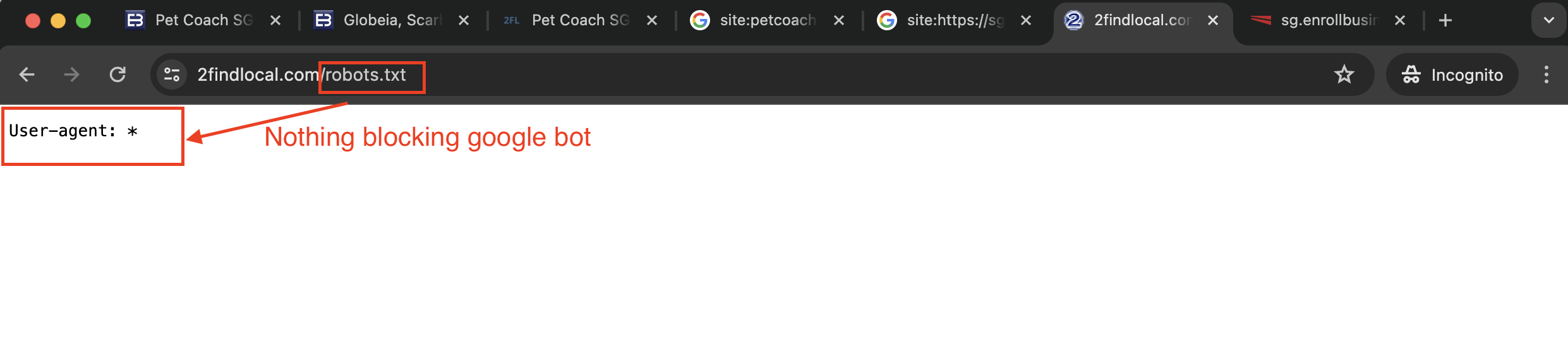
- Check the meta tags in the HTML to confirm there isn’t a
noindexdirective.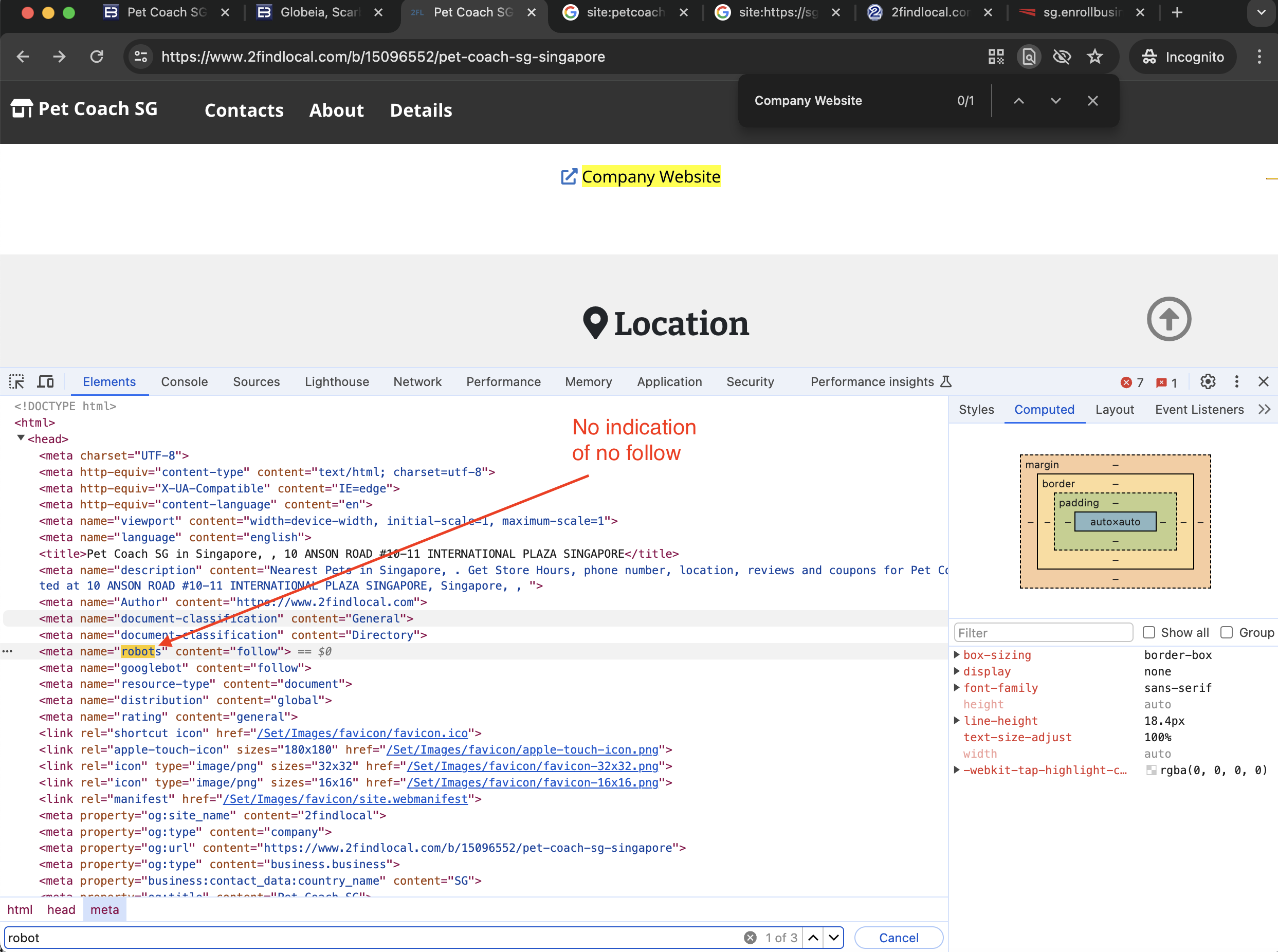
This means, theoretically, the directory pages should be indexable. We will proceed to the next steps, and then review the pages again after several days to check whether they have been indexed.
Step 2: Create an Indexable Page
We’ll create a new page that will definitely be indexed by Google. This page will include links pointing to the directory pages listing our website. Essentially, this blog post serves that purpose. The links can be found in this section!
The idea is that:
- Google will crawl this blog post, which contains links to the sgenroll and 2findlocal directories
- Google will subsequently crawl both those directory pages and recognize a backlink to Pet Coach SG
- Google will then register the backlinks from the directory pages to Pet Coach SG. This should appear in the Google Search Console
But to do that, we must first ensure that this blogpost is indexed! That’s covered in the next step!
Step 3: Request Indexing for Our Page
Once this blogpost is live, we’ll request Google to index it. This will ensure Google crawls our page and all links within it, including the directory pages. The steps to request for Google to index this page is stepped down below:
- Log into Google Search Console.
- Inspect the URL of the page to be indexed.
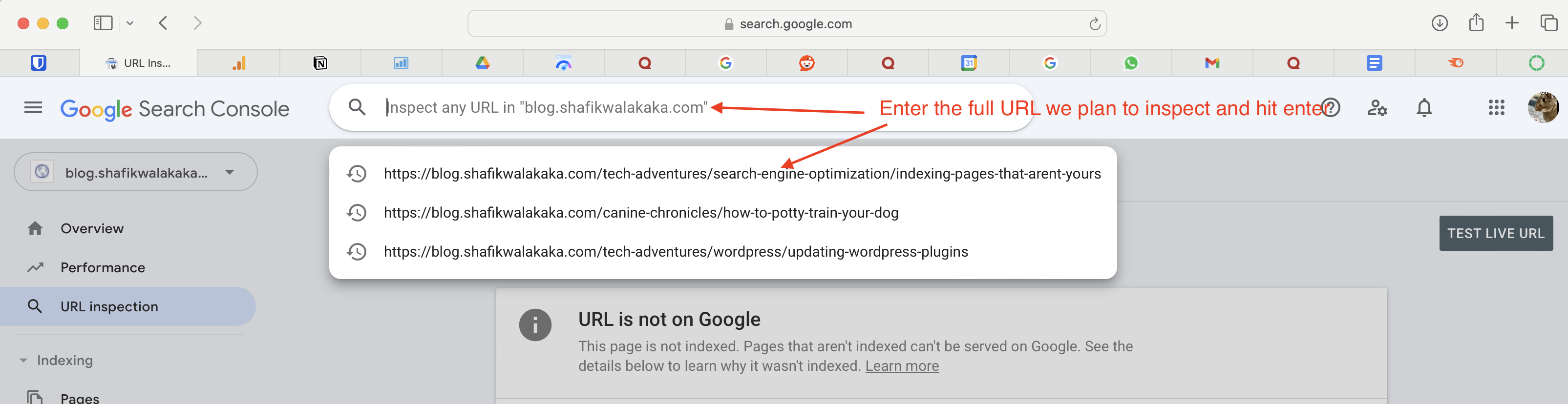
- Run live testing by clicking the ‘Test Live URL’ button.
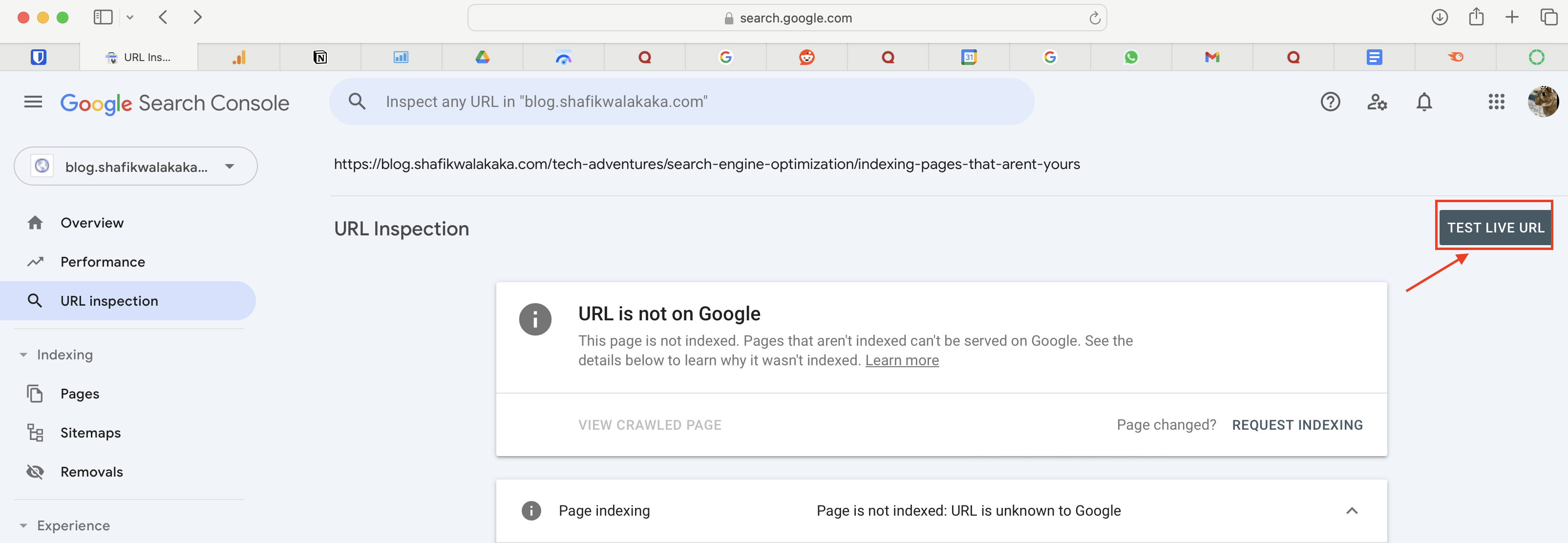
- If Google indicates the page can be indexed, click ‘Request Indexing’.
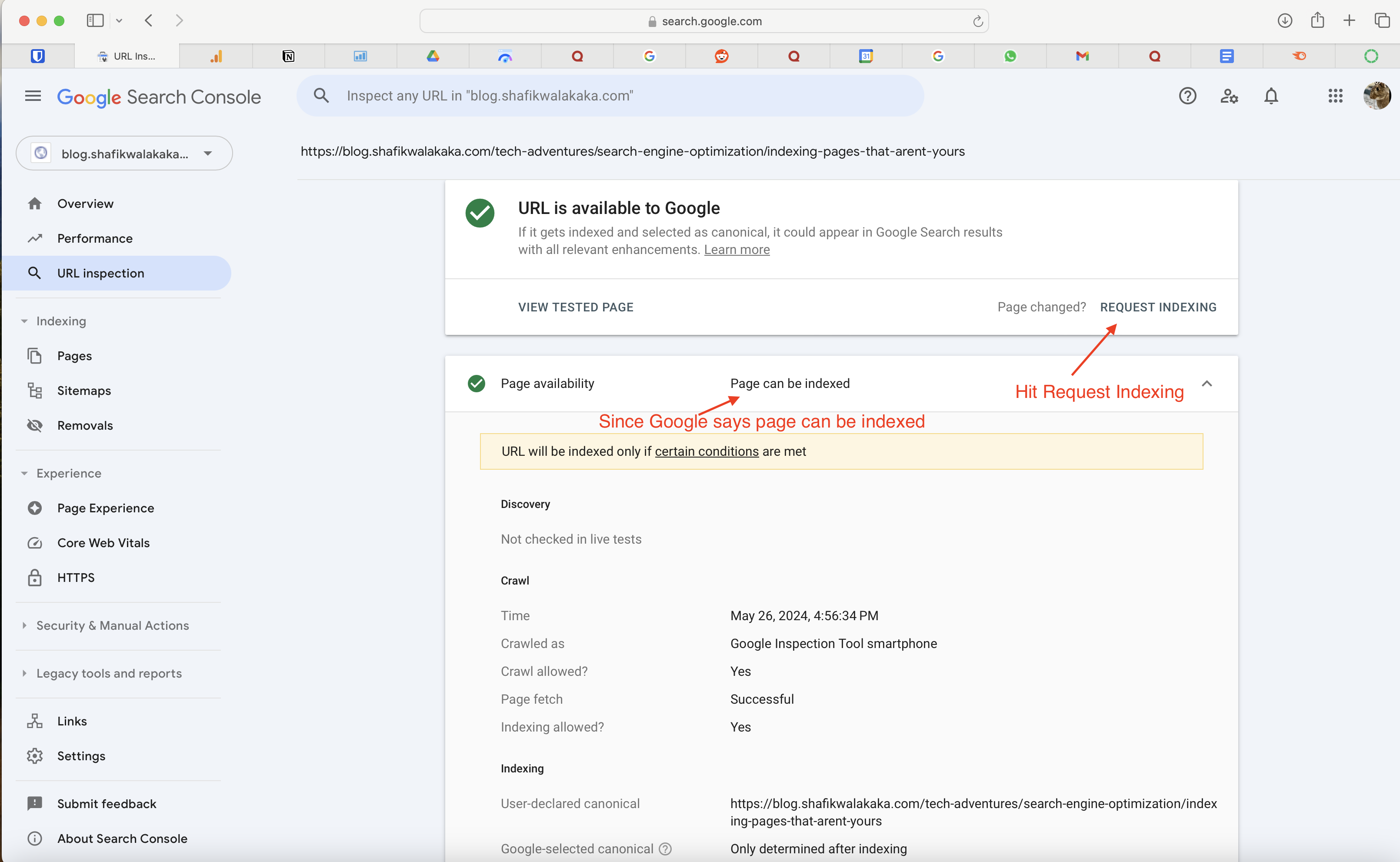
Why can’t we use the Google Search console to index the 2findlocal and sgenroll directory pages? Because we don’t own those pages, and we don’t have access to a Google Search Console that has verified access to those pages!
Next Steps: Revisiting the Pages
This is an experiment for us, as much as it is for you!
- If successful: Our approach works, and the pages get indexed. We can then review whether GSC indeeds registers the backlink from the directories.
- If not: We may need to explore alternative methods (back to square one ><)
We are ourselves interested in this experiment, and will provide an update to this page once the experiment is complete! So stay tuned ^^!
Frequently Asked Questions
What is a No Follow Link?
A nofollow attribute is added to a hyperlink to tell search engines not to pass any SEO value to the linked webpage. For further details regarding follow vs no follow links, checkout the article by Semrush here: SEMrush on Follow vs No Follow Links
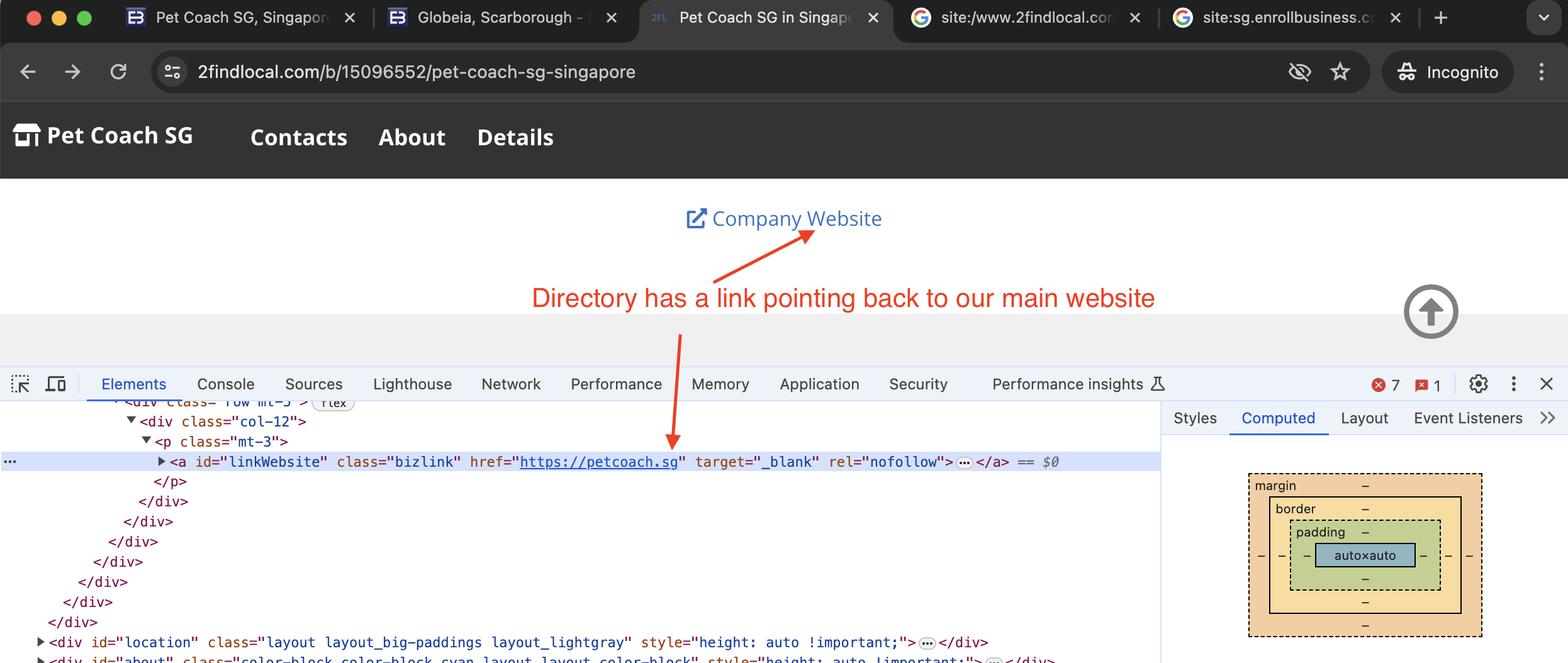
How to Check for No Follow Links
You can inspect links using developer tools in browsers to see if the rel="nofollow" attribute is present. See screenshot below of our Pet Coach SG listing in the 2findlocal directory for reference: 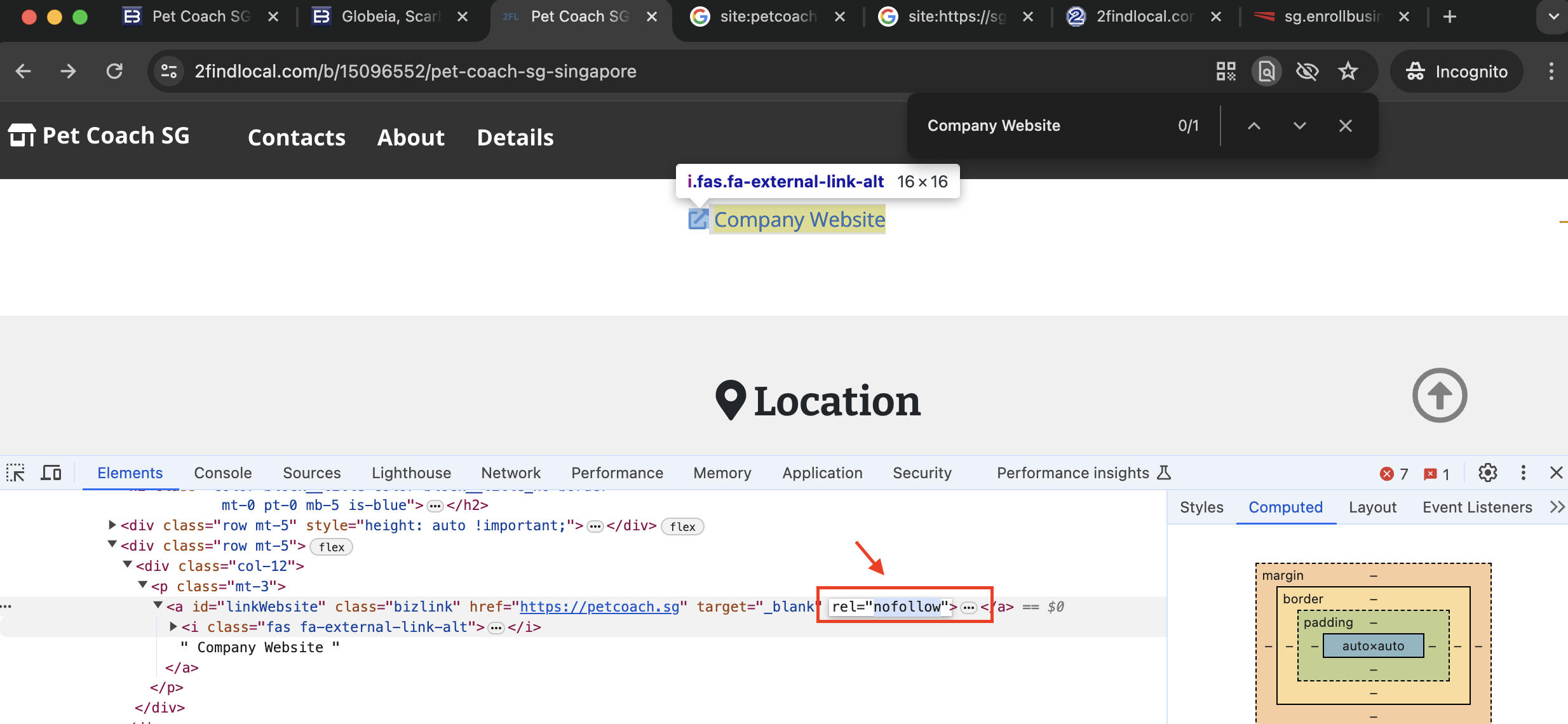
Impact of No Follow Links
While Google does follow nofollow links, it doesn’t give them as much weight as follow links. However, Google still follows the link, and the pages should still be indexed. See the detailed testing done by Backlinko in this article: Backlinko on No Follow Links
This means that even if a link is marked with nofollow, it can still contribute to your overall indexing efforts.
Why is it Legal to Index a Page that you don’t control?
We are only able to indirectly have Google crawl the page because the site owner did not explicitly prevent the page from indexing. The fact that the page is not indexed is probably more of an oversight rather than an explicit requirement not to index the page.
If you’d recall, we needed to check whether the directory site owner has explicitly specified that google cannot index the page. See this section for reference.
If the site owner has explicitly specified a robots.txt or a robots meta tag that prevents Google from indexing the page, Google will respect the directive.
Conclusion
Trying to get a page indexed that isn’t yours is a bit like navigating a labyrinth, but it’s certainly doable. Our experiment with creating an indexable page pointing to non-indexed directory listings serves as a practical approach to overcome this challenge.Stay tuned for updates on the success of this method, and feel free to share your experiences or ask any questions in the comments section below. Happy indexing!
Peace and Love
Shafik Walakaka