Automated Testing
Table of contents
We previously wrote an article on how much I hate updating plugins on wordpress:
- Need to update weekly
- After that need to test because site might break
This takes valuable time, and honestly – testing weekly just became too painful i stopped updating plugins frequently.
Issue
Recently though, a missed plugin udpate caused my site to break – or, possibily? We still don’t know the root cause but missing plugin updates can cause security issues etc., and is in general just pure bad practice lol.
So, I’ve finally set up some sort of automated testing. Not fully – just accessing the URLs, and then taking a screenshot. See sample of the screenshots that playwright has taken for me: 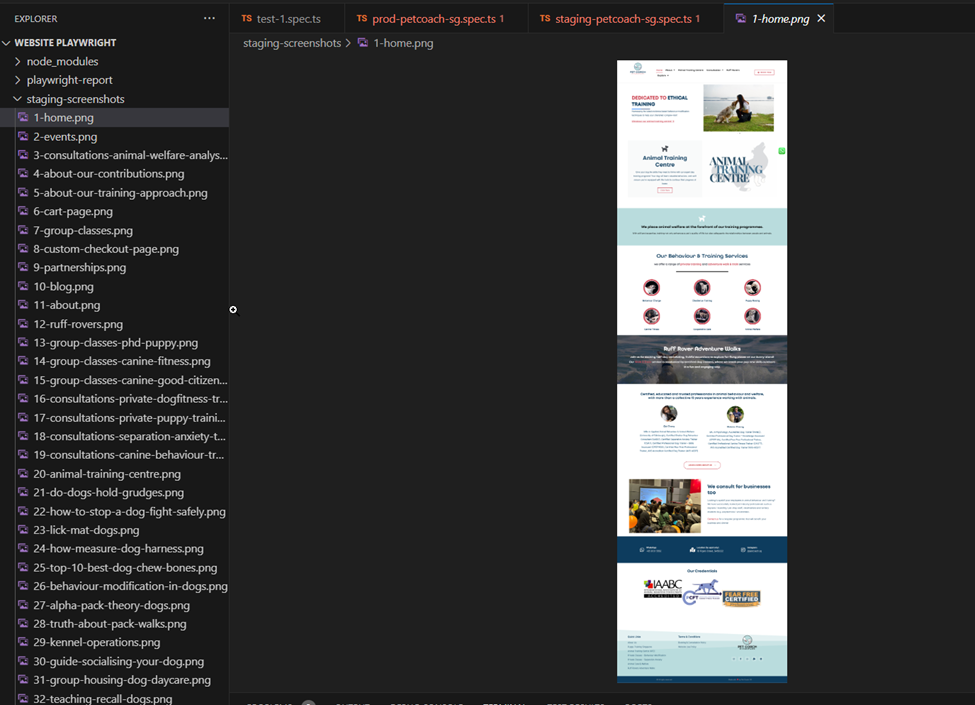
At least, by doing so – I don’t need to access every single page, wait for it to load and then inspect it.
This is definitely just the starting, ideally, I’d want to test every functionality so that I can be sure that when the test passes – my site is working fine.
But for now, this would do for a simple static site like this. Just need it to look good right?
So, how did I do it?
Playwright
Playwright is a microsoft developed tool to help you automate testing. At my workplace, we use it extensively – and professionals script it.
For me – I’m just fooling around with it to get familiar with the tool.
You can check out my full playwright script here!
I’ll step down what I’ve done for your reference:
Set the constants to get the URLs from the sitemap
As all the URLs are available in the sitemaps, I set the constants here! The constants consists of:
- Sitemap URLs
- response from the sitemap URLs
- The text from the sitemap URLs response. This is in xml format
- Parse for the xml
- The variable to store the combined URL:
urls
// Set URL constants
const sitemapUrl = 'https://staging.petcoach.sg/page-sitemap.xml';
const sitemapUrl2 = 'https://staging.petcoach.sg/post-sitemap.xml';
// Fetch both XML files
const response = await request.get(sitemapUrl);
const response2 = await request.get(sitemapUrl2);
// Extract XML content
const xml = await response.text();
const xml2 = await response2.text();
// Parse XML data
const parser = new xml2js.Parser();
// Merging URLs from both sitemaps into one array
const urls: string[] = [];
Retrieve the URLs from both sitemaps
Then I parse both sitemaps and extract the URLs, and store them in urls:
// Parse the first sitemap (page-sitemap.xml)
parser.parseString(xml, (err, result) => {
if (err) {
console.error('Failed to parse XML:', err);
return;
}
// Extract URLs
const urls1 = result.urlset.url.map((url: any) => url.loc[0]);
console.log('Extracted URLs:', urls1);
// Merge with the combined urls array
urls.push(...urls1); // Spread the URLs from page-sitemap.xml into the urls array
});
// Parse the second sitemap (post-sitemap.xml)
parser.parseString(xml2, (err, result) => {
if (err) {
console.error('Failed to parse XML for post-sitemap.xml:', err);
return;
}
// Extract URLs from the post sitemap
const urls2 = result.urlset.url.map((url: any) => url.loc[0]);
console.log('Extracted URLs from post-sitemap.xml:', urls2);
// Merge with the combined urls array
urls.push(...urls2); // Spread the URLs from post-sitemap.xml into the urls array
});
Playwright accesses each URL and takes a screenshot
// Access each URL sequentially and check page accessibility
for (let i = 0; i < urls.length; i++) {
//if (i === 3) break; // Break the loop after 5 URLs
const url = urls[i];
const context = await browser.newContext(); // ✅ New browser context per URL
const page = await context.newPage();
try {
// Access the URL in the browser
console.log(`Accessing URL: ${url}`);
await Promise.race([
(async () => {
console.log("promise race block starting...");
const pageResponse = await page.goto(url, { waitUntil: 'networkidle' });
// await page.goto(url, { waitUntil: 'load' }); // Wait until the DOM is loaded
// await page.goto(url, { waitUntil: 'networkidle' }); // Wait until the network is idle
await page.waitForTimeout(10000); // Wait for 10 seconds between requests
await scrollToBottom(page); // 👈 smooth scroll added here
await scrollToTop(page); // scroll back to the top for the screenshot
// Derive a clean path from the URL
const urlObj = new URL(url);
let pathname = urlObj.pathname.replace(/^\/|\/$/g, ''); // Trim slashes
if (!pathname) pathname = 'home'; // Fallback for root path `/`
const safePath = pathname.replace(/[^a-zA-Z0-9\-]/g, '-'); // Sanitize filename
const fileName = `${i + 1}-${safePath}.png`;
// Take screenshot after loading the page
//await page.screenshot({ path: `staging-screenshots/${i + 1}-screenshot.png`, fullPage: true });
await page.screenshot({ path: `staging-screenshots/${fileName}`, fullPage: true });
// Get the response status
if (pageResponse) {
const status = pageResponse.status();
console.log(`Status for ${url}:`, status);
} else {
console.log(`No response received for ${url}`);
}
// Perform assertion to ensure the page is accessible (status code 200)
expect(pageResponse.status()).toBe(200);
const title = await page.title();
expect(title.length).toBeGreaterThan(0);
})(),
new Promise((_, reject) =>
setTimeout(() => reject(new Error(`Timeout after ${TIMEOUT_MS / 1000} seconds`)), TIMEOUT_MS)
)
]);
} catch (error) {
console.error(`Error while testing ${url}:`, error);
}
Needed to scroll up, down
Needed to scroll up and down as some images are only loaded when you scroll over them
await page.waitForTimeout(10000); // Wait for 10 seconds between requests
await scrollToBottom(page); // 👈 smooth scroll added here
await scrollToTop(page); // scroll back to the top for the screenshot
Store the screenshots for review
I store the screenshots for my review later – playwright does the heavy lifting, and I just check it out:
// Derive a clean path from the URL
const urlObj = new URL(url);
let pathname = urlObj.pathname.replace(/^\/|\/$/g, ''); // Trim slashes
if (!pathname) pathname = 'home'; // Fallback for root path `/`
const safePath = pathname.replace(/[^a-zA-Z0-9\-]/g, '-'); // Sanitize filename
const fileName = `${i + 1}-${safePath}.png`;
// Take screenshot after loading the page
//await page.screenshot({ path: `staging-screenshots/${i + 1}-screenshot.png`, fullPage: true });
await page.screenshot({ path: `staging-screenshots/${fileName}`, fullPage: true });
See sample screenshots generated by playwright
You can see example screenshots generated by playwright here!
Now that we have the screenshots, my plugin update flow no longer requires me to do manual testing lol.
Revised Steps
Now, my update steps are straightforward!
- Firstly, update the staging site:

- To ensure no caching issues, I purged all the cache
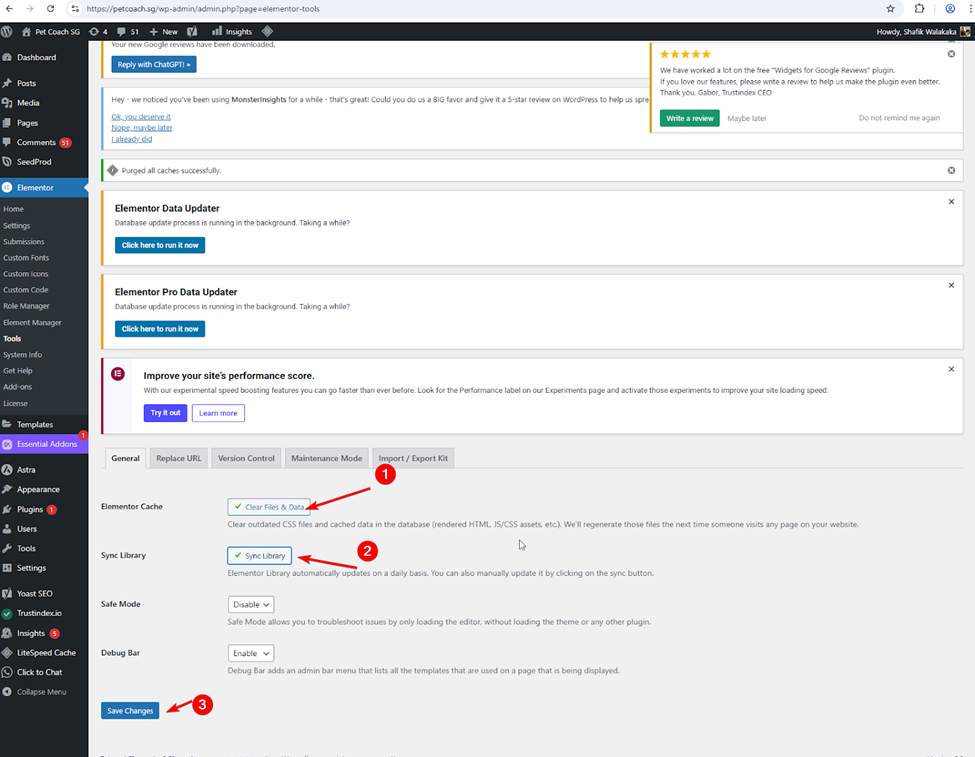
- Elementor cache – regenerate all css and files in elementor
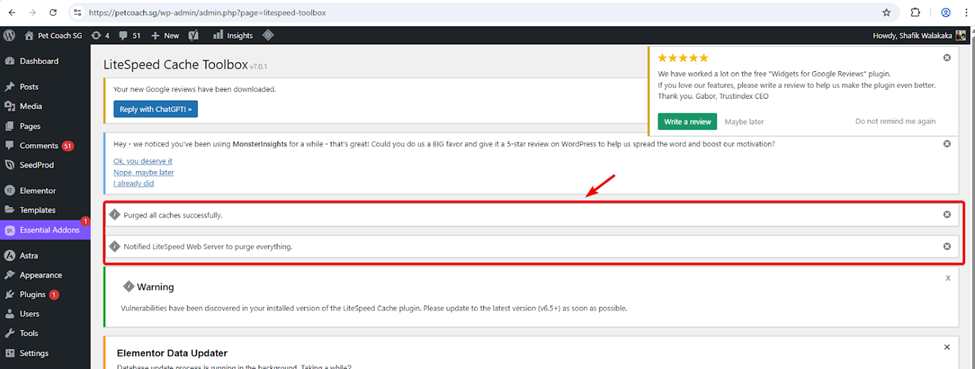
- Purge litespeed cache
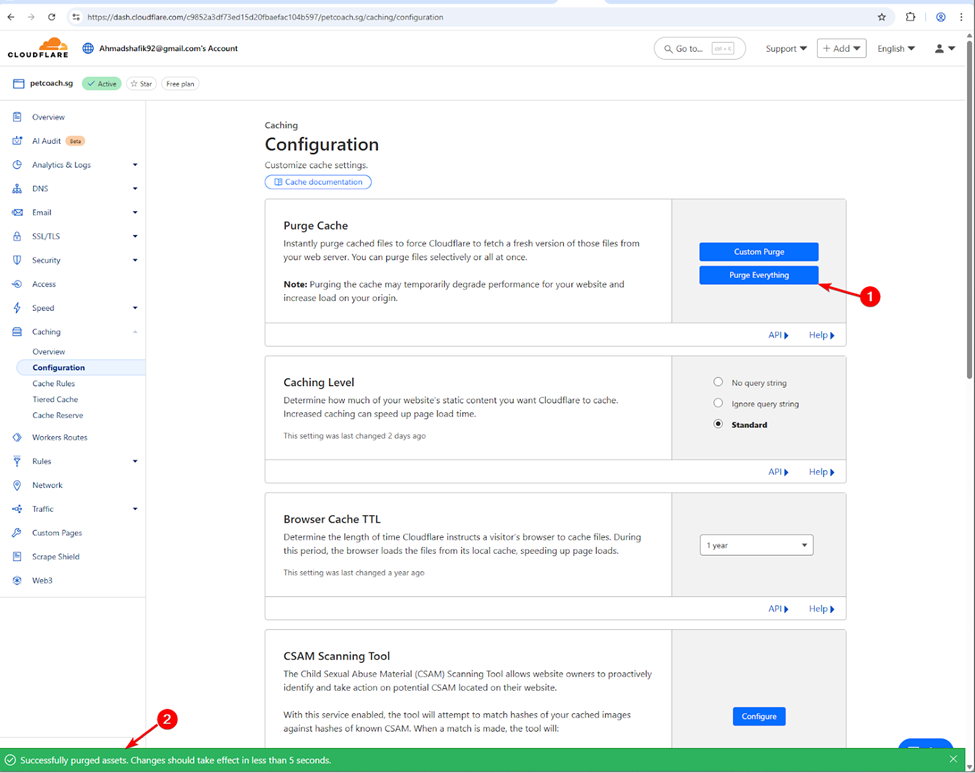
- Purge cloudflare cache
- Elementor cache – regenerate all css and files in elementor
- Next, I run the script and get screenshots of the staging site that I can manually inspect:
I just repeat the same flow for production, but now the script points to the production site instead of the staging site!
Conclusion, Benefits
Benefits are that now – I no longer have to manually access each individual URL. And Litespeed, it caches the html document – but only after you access it.
Previously, I had to access each individual pages, so that the doc is generated, and cached server side. However, now – playwright does it for me. When I access the page, it’s already blazing fast ;)!!